Reduce Infrastructure Demands with Parameter-Efficient Fine-Tuning (PEFT)

Chris James
CEO
Realistic LLM Options for Enterprise Deployment
While models like GPT-4 dominate headlines, they're not built for private infrastructure. Fortunately, a new generation of open-source large language models (LLMs) strikes the right balance between performance, efficiency, and deployability.
LLaMA 2 / 3 (Meta) Available in 7B and 13B parameter sizes, these models support quantization and are ideal for general-purpose enterprise tasks.
Mistral-7B (Mistral AI) Delivers fast inference and strong performance, even with fewer parameters—optimized for efficient hardware use.
Phi-3 (Microsoft) Compact and capable models ranging from 1.3B to 7B parameters, well-suited for on-device or latency-sensitive applications.
These models are compatible with deployment tools like vLLM, llama.cpp, and Hugging Face Transformers. When combined with quantization techniques (e.g., INT4/INT8), they can run on local GPU clusters—or even on consumer-grade GPUs—reducing memory, power consumption, and cooling needs.
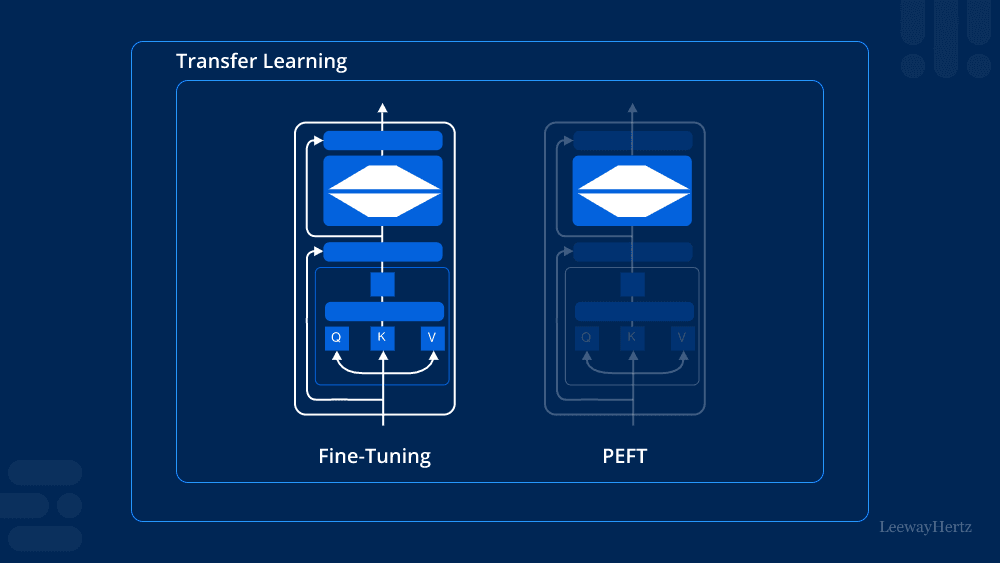
Fine-Tuning: Shift to Parameter Efficiency
Traditional fine-tuning involves retraining an entire model, often requiring dozens of GPUs and days of runtime. For most enterprise environments, that's not practical. Enter Parameter-Efficient Fine-Tuning (PEFT)—a smarter, lighter approach.
What PEFT Enables
- Targeted training: Only a small subset of model parameters are trained (e.g., using LoRA adapters).
- Minimal output footprint: Fine-tuned models are small and easy to version—often just a few megabytes.
- Resource efficiency: These techniques can be run on modest infrastructure, even laptops or single-GPU servers.
PEFT also enables:
- Faster experimentation and deployment.
- Lower total cost of ownership (TCO).
- Better compliance with security or data residency policies by avoiding cloud-hosted fine-tuning.
Why It Matters for Infrastructure Teams
Supporting PEFT isn't just an optimization—it's a strategic enabler. By building infrastructure that can support small-scale fine-tuning workflows:
- You reduce energy and cooling requirements.
- You maintain control over sensitive data.
- You enable agile, domain-specific AI development—without disrupting core systems.
The Bottom Line
You don't need to run billion-dollar models to unlock AI's potential. With the right combination of:
- Open-source LLMs (like LLaMA, Mistral, or Phi),
- Efficient deployment frameworks,
- And Parameter-Efficient Fine-Tuning methods,
…infra teams can support enterprise AI needs securely, cost-effectively, and sustainably.


